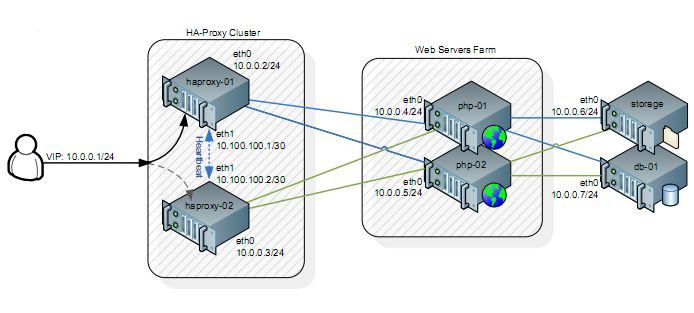
What is the main objective of this entire topology?
Redundancy and Load Sharing! Imagine a scenario where your single web server is receiving millions and millions of HTTP requests per second, the CPU load is going insane, as well as the memory usage, when suddenly “crash!”, the server dies without saying good-bye (probably because of some weird hardware out-stage that you certainly won’t have time to debug). Well, this simple scheme might lead you into a brand new world of possibilities.
What is this going to solve?
Hardware Failures! We are going to have redundant hardware all over the place, if one goes down, another one will be immediately ready for taking its place. Also, by using load sharing schemes, this is going to solve our High Usage! issue. Balancing the load among every server on our “farm” will reduce the amount of HTTP request per server (but you already figured that out, right?).
Let’s set it up! Firstly, we’re not going to use a domain scheme (let’s keep it simple), make sure your /etc/hosts file looks exactly like the picture below on every machine:
192.168.0.39 Node1
192.168.0.30 Node2
192.168.223.147 Node1
192.168.223.148 Node2
192.168.0.58 Web1
192.168.0.139 Web2
192.168.0.132 Mysql

That’s right. We are going to use a very handsome application named “heartbeat” as our first level redundancy, it will be responsible for keeping our HAProxy (our “Reliable, High Performance TCP/HTTP Load Balancer”) redundant. Don’t you agree that having only ONE load balancer means there’s a single point of failure? Well, redundancy is all about overthrowing this statement, we shall never have a single point of failure, and that’s why we are not deploying a single HAProxy.
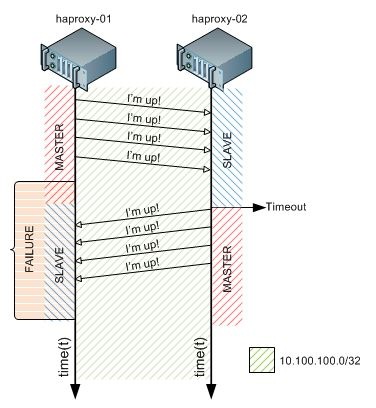
Setting up the heartbeat is easy, after the installation you will need to create those files on both servers (Node1 and Node2):
node Node2
IPaddr::192.168.0.241/24/eth0 lampp
mode http
stats enable
stats auth admin:polaris # Change this to your own username and password!
balance roundrobin
option httpclose
option forwardfor
cookie JSESSIONID prefix
server web1 192.168.0.58:80 cookie A check
server web2 192.168.0.139:80 cookie B check
node Node2
IPaddr::192.168.0.241/24/eth0 lampp
mode http
stats enable
stats auth admin:polaris # Change this to your own username and password!
balance roundrobin
option httpclose
option forwardfor
cookie JSESSIONID prefix
server web1 192.168.0.58:80 cookie A check
server web2 192.168.0.139:80 cookie B check
(cannot bind socket) on haproxy-02, this happened because the kernel is not ready (by default) to bind this kind of socket to a remote machine. By this moment, the virtual IP address belongs to the master node (haproxy-01), this why haproxy-01 started the haproxy without any problems. The solution lies here: