Here we’ll see how to remove duplicate entries from sorted Linked List using C Programming. In the previous article we saw how to remove duplicate entries from a generic linked list which will work here for sorted linked list also. But we’ll see how to take advantage of the sorted list and improve the performance of the algorithm. Running time of the previous algorithm was O(n2) but running time of the algorithm discussed here is O(n).
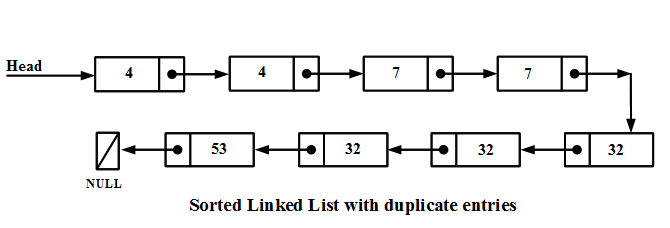
The above diagram is an example of a sorted linked list. One thing you should notice is that the duplicate entries always comes together in case of sorted linked list. After removing the duplicate entries from the above list, the result will look like the diagram below.

C Program to Remove Duplicate Entries from a Sorted Linked List
#include <stdio.h>
#include <stdlib.h>
struct node{
int val;
struct node *next;
};
void print_list(struct node *head)
{
printf("H->");
while(head)
{
printf("%d->", head->val);
head = head->next;
}
printf("|||\n");
}
void insert_sorted(struct node **head, int value)
{
struct node * new_node = NULL;
struct node * tmp_node = NULL;
new_node = (struct node *)malloc(sizeof(struct node));
if (new_node == NULL)
{
printf("Failed to insert element. Out of memory");
}
new_node->val = value;
if(*head == NULL || value < (*head)->val)
{
new_node->next = *head;
*head = new_node;
return;
}
tmp_node = *head;
while(tmp_node->next && value > tmp_node->next->val)
{
tmp_node = tmp_node->next;
}
new_node->next = tmp_node->next;
tmp_node->next = new_node;
}
void delete_node(struct node **head, struct node *node)
{
struct node *tmp = NULL;
if (head == NULL || *head == NULL) return;
if(*head == node)
{
/*Delete the head node*/
*head = (*head)->next;
free(node);
return;
}
tmp = *head;
while(tmp->next && tmp->next != node) tmp = tmp->next;
if(tmp->next)
{
tmp->next = tmp->next->next;
free(node);
}
else
{
printf("Node not found in the list.\n");
}
}
void remove_duplicate(struct node *head)
{
struct node *tmp = NULL;
struct node *tmp1 = NULL;
if (head == NULL) return;
tmp = head;
tmp1 = tmp->next;
while(tmp && tmp1)
{
if(tmp->val == tmp1->val)
{
delete_node(&head, tmp1);
tmp1 = tmp->next;
continue;
}
tmp = tmp->next;
if(tmp) tmp1 = tmp->next;
}
}
void main()
{
int count = 0, i, val;
struct node * head = NULL;
printf("Enter number of elements: ");
scanf("%d", &count);
for (i = 0; i < count; i++)
{
printf("Enter %dth element: ", i);
scanf("%d", &val);
insert_sorted(&head, val);
}
printf("Initial List: ");
print_list(head);
remove_duplicate(head);
printf("List after removing duplicate entries: ");
print_list(head);
}
Output of the above program
Enter number of elements: 10 Enter 0th element: 32 Enter 1th element: 4 Enter 2th element: 53 Enter 3th element: 32 Enter 4th element: 65 Enter 5th element: 4 Enter 6th element: 65 Enter 7th element: 32 Enter 8th element: 7 Enter 9th element: 7 Initial List: H->4->4->7->7->32->32->32->53->||| List after removing duplicate entries: H->4->7->32->53->|||
Explanation
The algorithm is simple. Traverse the linked list with two pointers pointing to consecutive nodes starting from the head. If the values of two nodes are equal, delete the second node, and point the second pointer to the element next to the deleted node, otherwise move both pointers to one position.
void remove_duplicate(struct node *head)
{
struct node *tmp = NULL;
struct node *tmp1 = NULL;
if (head == NULL) return;
tmp = head;
tmp1 = tmp->next;
while(tmp && tmp1)
{
if(tmp->val == tmp1->val)
{
delete_node(&head, tmp1);
tmp1 = tmp->next;
continue;
}
tmp = tmp->next;
if(tmp) tmp1 = tmp->next;
}
}
This remove_duplicate() function implements the above algorithm. tmp is is initialized with head and tmp1 with next pointer of head. We have a loop until one of them becomes NULL. Inside the loop we are comparing the values of two nodes pointed by tmp and tmp1. If they are equal we are deleting the node pointed by tmp1 and assigning tmp1 with next of tmp and also continuing the loop without advancing tmp. If they are not equal we are continuing the loop after advancing both tmp and tmp1.